Я тут пообещал поделиться опытом оптимизации SQL запросов. Мне достаточно много приходилось работать над оптимизацией и на работе не раз просили рассказать, как я оптимизирую запросы. Тут нет какого-то секрета и, хотя я пытался поделиться, это все же такой процесс, в котором мастерство приходит с опытом.
На блоге я уже несколько раз делился некоторыми отдельными случаями, но пришла пора все же более подробно рассмотреть эту тему.
Это вводная часть, где я расскажу в статье и покажу в видео (его можно найти в конце этой статьи) базовые вещи о индексах и статистике.
О индексах и статистике можно писать очень много и возможно будет еще статья и видео. А это такой вводный курс, чтобы показать базу.
Когда я узнаю о том, что на сервере есть медленно выполняющийся запрос, первое на что я смотрю – статистику io. Это такое слабое звено, позволяет быстро определить легкие проблемные места SQL запросов.
В SQL Server есть несколько вариантов получения данных о том, как выполняется запрос – но именно статистика получается очень легко и тут же показывает проблемные места в читабельном виде.
Второй популярный способ – смотреть на план выполнения, но в случае с большими и сложными запросами план выполнения может быть не таким уж и наглядным, а по статистике чтений можно тут же увидеть, на какую таблицу идет нагрузка, потом посмотреть по каким полям в запросе происходит фильтрация данной таблицы и убедится, что по этим полям есть индекс.
Давайте займемся тем, чем любят заниматься программисты по ночам – посмотрим на код. Итак, для вводного курса рассмотрим простой пример с запросом:
select * from Member where WSEmail = 'noreply@flenov.info'
У меня в тестовой базе данных почти 200 тысяч записей и поиск по ней происходит мгновенно. Если посмотреть на время выполнения, то будет ноль секунд, что очень хорошо. Но давайте включим отображение статистики, и посмотрим на нее. Я всегда включаю статистику io и время time:
set statistics io on set statistics time on
Теперь после выполнения SQL запроса в SQL Management Studio внизу окна будет появляться не только результат, но и на закладке Messages будет показана статистика выполнения:
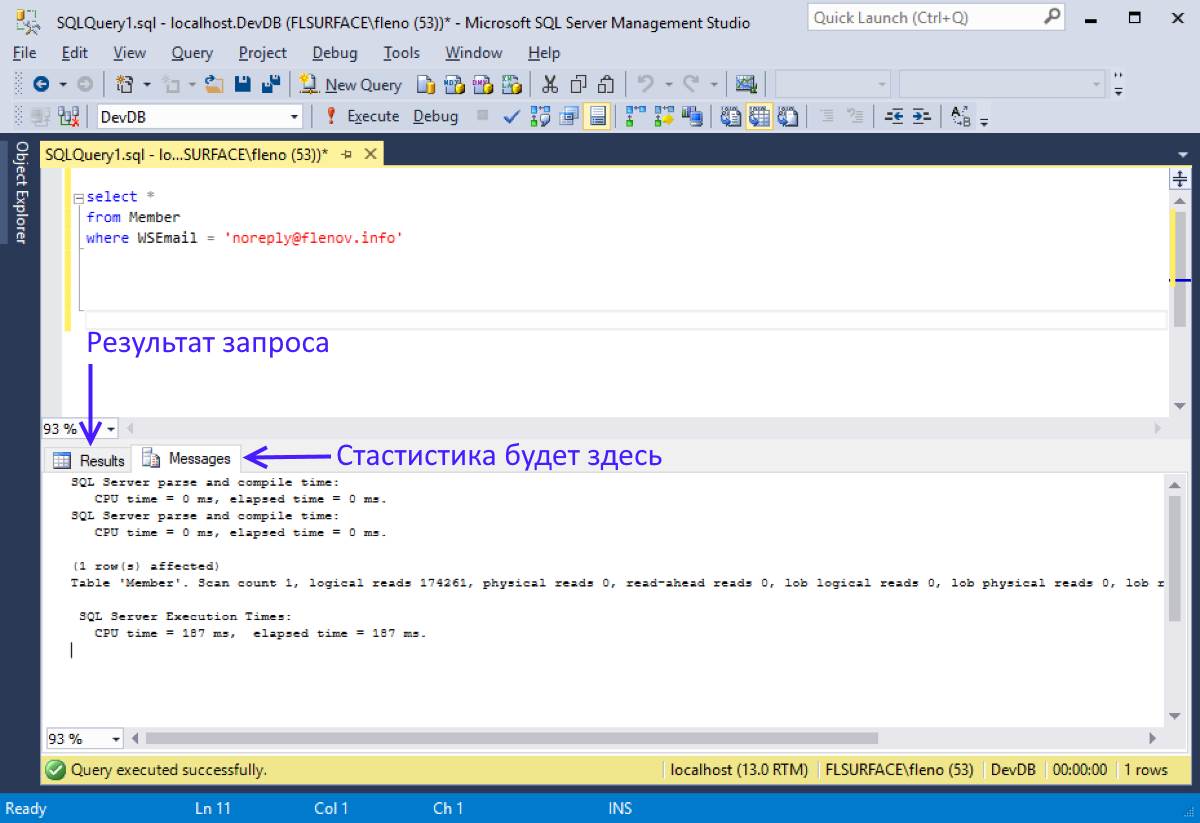
В моем случае статистика выглядела так:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (1 row(s) affected) Table 'Member'. Scan count 1, logical reads 174261, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 187 ms, elapsed time = 187 ms.
Первые четыре строчки – это время компиляции запроса и для такого простого особо проблем не должно возникнуть, а я уже выполнял запрос, поэтому и 0 секунд.
После этого идет статистика выполнения и тут нужно смотреть на количество сканирований и количество чтений (logical reads, physical reads и др). У нас сейчас запрос простой, который решается одним сканированием. Судя по количеству чтений, сканировалась абсолютно вся таблица.
Казалось бы, да и черт с ним, что сканируется вся таблица, если запрос выполняется так быстро – ноль секунд. И если запрос выполняется только один раз, то можно и забыть и забить. Но если сразу тысяча человек будет выполнять этот запрос и искать по разной фамилии? Даже при такой статистике нагрузка на базу данных будет серьезная, а если в базе будет миллион записей, то сервер может серьезно затормозить.
Для оптимизации нужно создать индекс, который ускоряет поиск:
create index IX_Member_WSEmail on Member ( WSEmail )
Более подробно о создании индексов можно почитать здесь: Индексы в MS SQL Server и еще немного интересной информации о индексах здесь: опции индексов.
Здесь я только скажу, что при создании индексов на таблицу, где много данных и с большим количеством выполняемых запросов может стать проблемой. Создание индекса по умолчанию потребует блокировки, что может стать препятствием. Индекс может не создаваться, потому что данные заблокированы или сайт может лечь, если индекс будет долго создаваться. Чтобы этого не произошло, нужно добавлять опцию: (online = on)
create index IX_Member_WSEmail on Member ( WSEmail ) with (online = on)
Снова выполняем запрос и смотрим на статистику:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 2 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (1 row(s) affected) Table 'Member'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Обратите внимание на количество чтений. Вот теперь даже если сотня тысяч пользователей будет выполнять такой запрос даже на многомиллионной базе, сервер скорей всего выдержит.
Попробуем взглянуть на план выполнения – графическое представление того, как сервер реально выполнял запрос. Для этого включаем опцию отображения плана – в меню Query выбираем Include Actual Execution Plan (или нажимаем Ctrl+M). Если теперь выполнить запрос, то появится еще одна вкладка – Execution Plan:
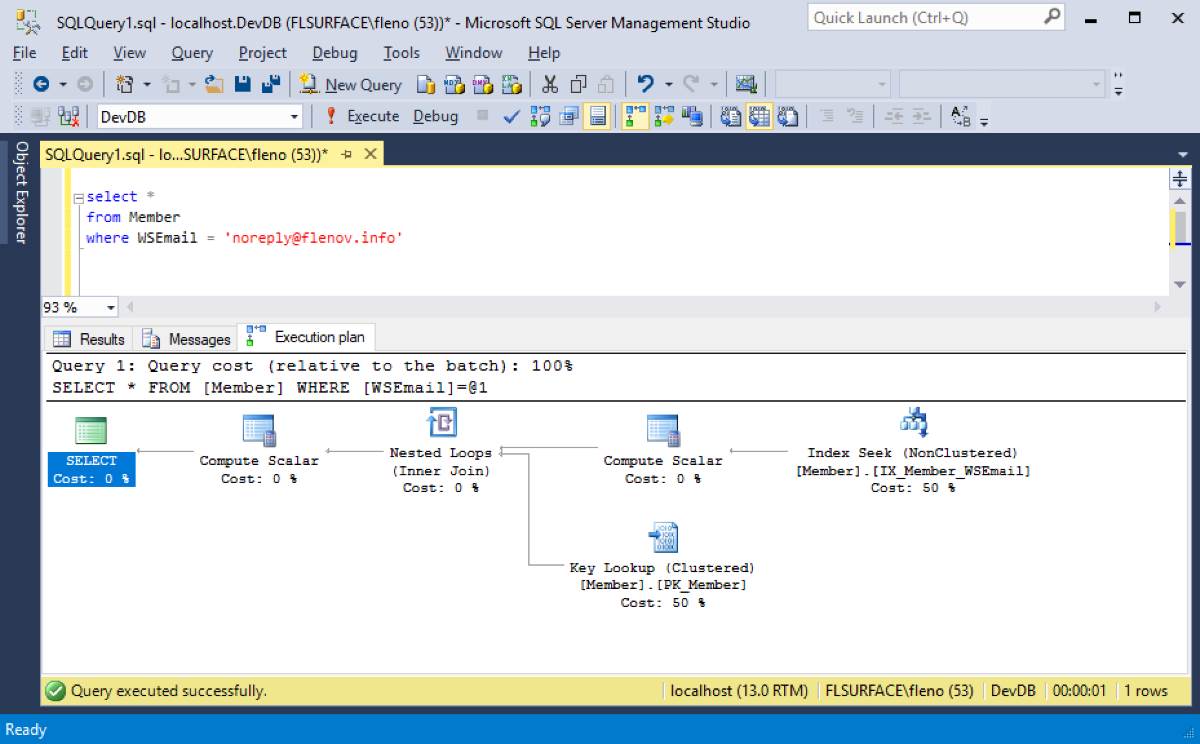
Здесь у нас две ветки и читать их нужно справа на лево. Самый правый блок – это то, с чего началось выполнение – Index Seak по индексу IX_Member_WSEmail. Наш простой запрос ищет данные по колонке WSEmail и эта колонка есть в индексе IX_Member_WSEmail, поэтому имеет смысл использовать его. И как мы уже увидели после создания индекса, результат как говориться на io. В индексе находятся индексируемые колонки и первичный ключ. Это все, что узнает сервер, когда находит строку по индексу. Но наш запрос выводит совершенно все колонки и чтобы найти оставшиеся данные, серверу приходится по первичному ключу находить их. Этот процесс быстрый – Key Lookup, потому что это первичный ключ, но он все же отнимает немного времени. И скоро мы увидим сколько. Получается, что серверу необходимо выполнить как бы две операции – поиск по индексу основного ключа, а потом по этому ключу найти данные колонок. А если выводить на экран только колонки WSEmail и первичный ключ MemberID? Эти данные уже есть индексе и второй Key Lookup не понадобиться. Посмотрим, как это будет выглядеть в статистике:
select WSEmail, MemberID from Member where WSEmail = 'noreply@flenov.info'
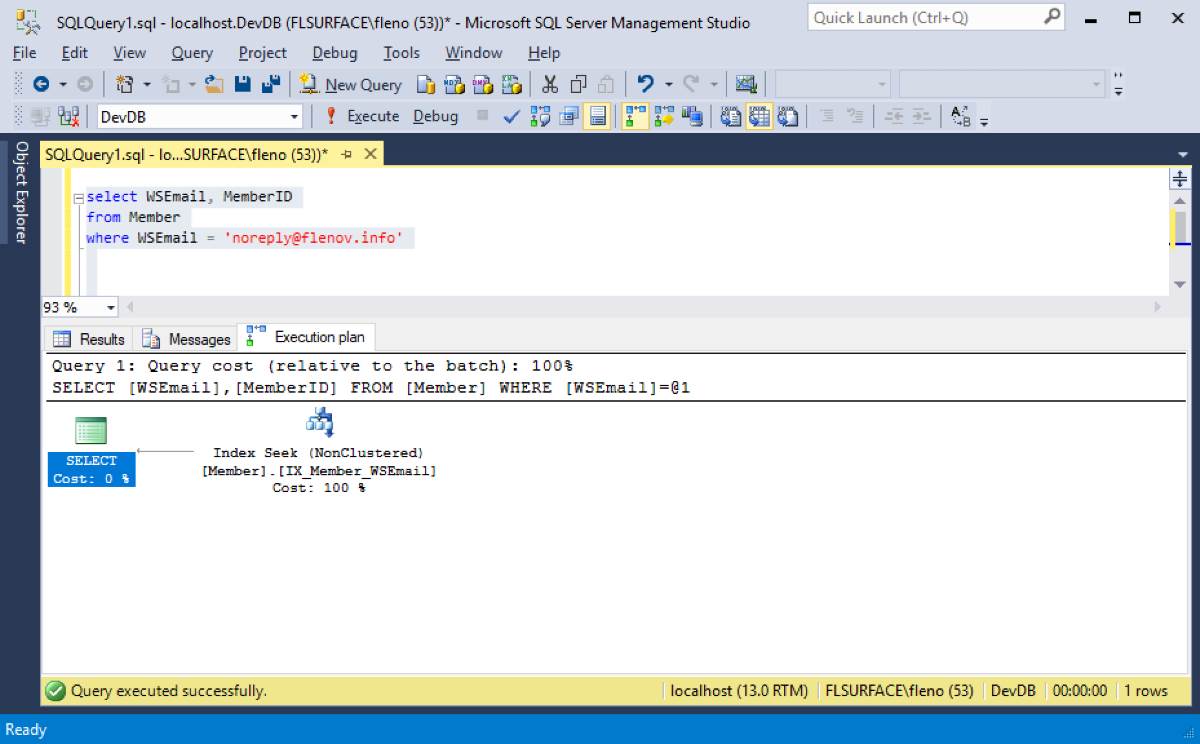
Статистика падает с 7 чтений до 3:
(1 row(s) affected) Table 'Member'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
А план выполнения начинает выглядеть идеально просто:
Допустим, нам необходимо вывести на экран имя человека, в моем случае это колонка WSFirstName:
select WSEmail, MemberID, WSFirstName from Member where WSEmail = 'noreply@flenov.info'
Теперь запросу нужно будет снова делать два поиска – чтобы найти первичный ключи, а потом по нему найти реальную строку, чтобы выцепить имя. И это в принципе не страшно, потому что поиск по первичному ключу занял всего 4 операции чтения, но что, если выводиться 1000 строк? Тогда уже будет 4000 операций. А если запрос у нас не такой простой и в нем потом еще есть left join на какую-то другую таблицу с именами, где, по имени храниться судьба человека (такой гороскоп по имени).
Можно создать индекс, который будет индексировать по email и по имени:
create index IX_Member_WSEmail on Member ( WSEmail, WSFirstName )
И хотя запрос фильтрует данные только по e-mail, этот индекс все же будет работать и позволит нам быстро найти данные, и в индексе будет уже имя и поэтому второй поиск уже не нужен будет. Круто, но не совсем эффективно. Имя меняется не часто и если мы по нему реально не ищем, то по нему индексировать смысла нет, но есть возможность сказать серверу, чтобы он хранил вместе с индексом еще и колонку WSFirstName, для этого есть такая фишка, как include:
create index IX_Member_WSEmail on Member ( WSEmail ) include(WSFirstName)
Теперь данные индексируются только по колонке WSEmail, что нам и нужно, но вместе с индексом храниться не только первичный ключ, но и имя.
Конечно же, теперь при обновлении данных в колонке WSFirstName придется обновлять и индекс, но так как мы не индексируем по этой колонке, то к перестроению данных это не приведет. Такая операция будет очень быстрой.
Еще один пример, который может выиграть от такого индекса:
select * from Member where WSEmail like 'noreply%' and WSFirstName = 'Михаил'
Мы выводим все колонки и от второго поиска по первичному ключу всех данных не убежать. Все колонки включать в индекс смысла нет, потому что это превратить его практически в первичный, просто не кластерный. Но.. Когда сервер отфильтрует данные по WSEmail по первому индексу и найдет допустим 1000 строк, он может тут же сократить эти данные и проверить имя и результат сократиться до (допустим) 100 строк. То есть Key Lookup может выполняться только 100 раз. Если колонка WSFirstName не включена в индекс, то эту операцию придется уже делать 1000 раз.
Чтобы индексы работали наиболее эффективно, тип данных значения и колонки должно совпадать. Как видите, в моем случае я просто передаю строку в одинарной кавычки, как varchar, потому что колонка имеет тип именно varchar. Если попробовать передать nvarchar:
select * from Member where WSEmail = N'noreply@flenov.info'
Теперь строка e-mail адреса передается в качестве nvarchar и это серьезно ударит по производительности. Изменился только тип строки, которую мы сравниваем, а посмотрите как обрушилась статистика:
(1 row(s) affected) Table 'Member'. Scan count 1, logical reads 684, physical reads 0, read-ahead reads 408, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Или вот такой пример, так обычно делают многие движки, когда выполняют запросы и примерно так будет выполнять запросы популярный Dapper или даже .NET фреймворк:
declare @email nvarchar(200) = N'noreply@flenov.info' select WSEmail, MemberID from Member where WSEmail = @email
Когда вы в .NET выполняете запрос, то создается переменная и она передается запросу.
Когда я работал над сайтом регистрации продуктов для Sony, то допустил такую ошибку. На главной странице сайте есть автокомплитер, где пользователь может ввести код товара. Пока пользователь вводит, на заднем плане происходит поиск и когда я запустил этот сайт, то он нереально затормозил, хотя этот сайт не такой уж и популярный и по посещаемости самый слабый из всех, что я делал для Sony. Начали исследовать, а оказалось, что для этого проекта я перешел на Dapper, который по умолчанию все переменные делал nvarchar, а в базе данных у нас все было просто varchar (сайт только для США). В результате, даже небольшой нагрузки на сайт хватало для серьезного падения производительности. Пришлось хакать Dapper, чтобы он не создавал переменные Unicode, а делал их простыми varchar
Если тип колонки и искомого значения совпадают, то будет использоваться Index Seek. Если не совпадают, то Index Scan – сканирование по индексу. Что используется для поиска можно увидеть в Execution Plan
Серверу придется просканировать весь индекс. За счет того, что он занимает меньше места на диске, то поиск будет быстрее, чем сканирование по данным, но все же на много медленнее, чем могло быть при правильном использовании параметров.
Если ваш фреймворк косячит и передает неверно параметры, а у вас нет доступа к исходникам, чтобы исправить, то можно использовать вот такой финт ушами:
declare @email varchar(200) = 'noreply@flenov.info' select WSEmail, MemberID from Member where WSEmail = cast(@email as varchar)
Здесь я с помощью cast привожу email переменную к правильному типу, чтобы он совпадал с типом данных колонки.
На этом наверно остановимся, для первого вводного курса этого должно быть достаточно. Если эта статья оказались интересна, рекомендую все же посмотреть еще и видео. Лайкни его, мне приятно видеть, если моя работа полезна и интересна другим. Подпишись на канал. Если будет востребованность, будет смысл продолжать эту тему.
Если будет продолжение, то со статистикой мы еще столкнемся не раз.
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Паника, что-то случилось!!! Ничего не найдено в комментариях. Срочно нужно что-то добавить, чтобы это место не оставалось пустым.

Программист, автор нескольких книг серии глазами хакера и просто блогер. Интересуюсь безопасностью, хотя хакером себя не считаю
Copyright © 2025 Михаил Флёнов. Тираж 1 штука. Отпечатано на ноутбуке. А за права отвечаю, или постараюсь.
А здесь еще и копирайт поставлю: Professional Web Development.
На сайте используются Cookie. Если вы из ЕС или Калифорнии США, то вы должны согласиться с их использованием - Согласен. Если вы из нормальной страны, то вам пох.


Добавить Комментарий