В прошлом видео я показал, как работают индексы, как они влияют на статистику выполнения запросов, и мы на примерах увидели план выполнения SQL.
Теперь я хочу поговорить о том, когда в действительности нужно создавать индекс, чтобы от него было больше пользы, чем вреда. Кажется, я уже говорил, на одной таблице может быть по 10 индексов, особенно, если на этой таблице чаще происходит в ставка, чем удаление. На таблице с сотней миллиардов записей у меня было 5 индексов, и вставка происходила вполне пристойно. Каждый день в этой таблице создавалось по миллиону записей минимум, а были дни, когда вставлялось десятки миллионов.
SQL сервер достаточно эффективно работает с индексами, потому что хранит данные в страницах, которые заполняются данными только до определенного уровня и этот уровень можно контролировать. Если вы знаете, что данные в базу вставляются часто и в разные места, то можно создать индекс, где страницы с данными заполнены наполовину.
Когда добавляется новая запись, то SQL сервер по индексу быстро находит нужную страницу, куда нужно добавить запись. В первом видео мы убедились, что поиск по индексу происходит очень быстро. Теперь если в странице есть место, то в нее просто добавляются данные о новой записи. Если места нет, то происходит деление, как у амеб. Страница делится пополам и в обоих из них появляется место для новых записей.
Из моего опыта с обновлением дело чуть хуже. Как я понимаю, серверу нужно найти две страницы – со старым значением индекса и с новым. Потом старое значение удалить и новое добавить. И хотя эта операция тоже достаточно быстрая, лучше все же ей не злоупотреблять. Если происходит частое обновление или вставка данных, чаще чем чтение, то возможно индекс и не нужен? Возможно, и давайте поговорим на эту тему.
Когда точно нужны индексы, ну почти точно. В общем, случаи, когда вероятность необходимости индекса очень высокая:
1. Первичный ключ – кажется все реляционные базы данных сразу же по умолчанию создают индекс на первичный ключ. В Microsoft SQL Server первичный ключ по умолчанию создает еще и кластерный индекс. Это не просто крутое название, оно означает, что именно по этому индексу физически отсортированы данные.
Если у простого индекса на самом последнем уровне дерева (листья) хранятся ссылки на то, где хранятся данные, то в кластерном там находятся сами данные.
Помните в первом видео я показывал, что в индексе находится первичный ключ. Все потому, что он у меня кластерный и первичный ключ это как раз и есть указатель на физическое положение данных.
Я даже не могу себе представить таблицу, в которой бы первичный ключ был бы без индекса.
2. Внешний ключ (Foreign Key). Допустим, что у вас есть две таблицы Person и Address. Скорей всего вам придется писать запросы типа:
select *
from Member m
join Address a on m.MemberID = a.MemberID
Внешние ключи указывают на то, что тут будет связь, а значит каждый раз, когда мы выполняем такой запрос, будет использоваться поиск. Внешние ключи обеспечивают целостность данных – нельзя удалить человека, если у него есть адреса и нельзя вставлять адрес для не существующего человека.
Если есть индекс, то убиваем его:
if (exists (select null from sys.indexes
where Name = 'IX_Address_MemberID' and object_id = object_id('address')))
drop INDEX [IX_Address_MemberID] ON [dbo].[Address]
Создаем внешний ключ:
alter table [Address] add constraint FK_Address_MemberID FOREIGN KEY ( MemberID ) references Member (MemberID)
Попробуем посмотреть статистику поиска адреса по связанной таблице:
select *
from Member m
join Address a on m.MemberID = a.MemberID
where m.MemberID = 7000041
В моем случае запрос вернул всего две записи, а статистика ужесна:
Table 'Address'. Scan count 1, logical reads 9699, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Member'. Scan count 0, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
9699 логических операций чтения по таблице Адреса – это ужасно. Такое просто недопустимо.
CREATE NONCLUSTERED INDEX [IX_Address_MemberID] ON [dbo].[Address] ( [MemberID] ASC )
Создаем индекс и снова смотрим на статистику:
(2 row(s) affected)
Table 'Address'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Member'. Scan count 0, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Вот это другая песня:
Снова удалим индекс и посмотрим на операцию удаления записи из таблицы Member:
if (exists (select null from sys.indexes
where Name = 'IX_Address_MemberID' and object_id = object_id('address')))
drop INDEX [IX_Address_MemberID] ON [dbo].[Address]
begin tran
delete from Member
where MemberID = 2
rollback
Физического удаление не нужно, поэтому я откатываю транзакцию.
Посмотрим на статистику, которая в моем случае выглядит так:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Member'. Scan count 0, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Вроде бы все прекрасно, только четыре логических чтения. Но статистика бывает обманчива и это один из тех случаев. Такое бывает редко, но все же такой быстрый взгляд может ввести в заблуждение.
Включите отображение плана выполнения. Обратите внимание, что помимо удаления по кластерному индексу есть еще и сканирование по кластерному индексу и эта операция заняла аж 14 процентов. Просто внешний ключ требует обеспечения целостности данных, а при удалении человека сервер должен убедиться, что нет адресов, которые ссылаются на этого человека. Ведь если адрес ссылается на удаленного человека, то это нарушение целостности внешнего ключа.
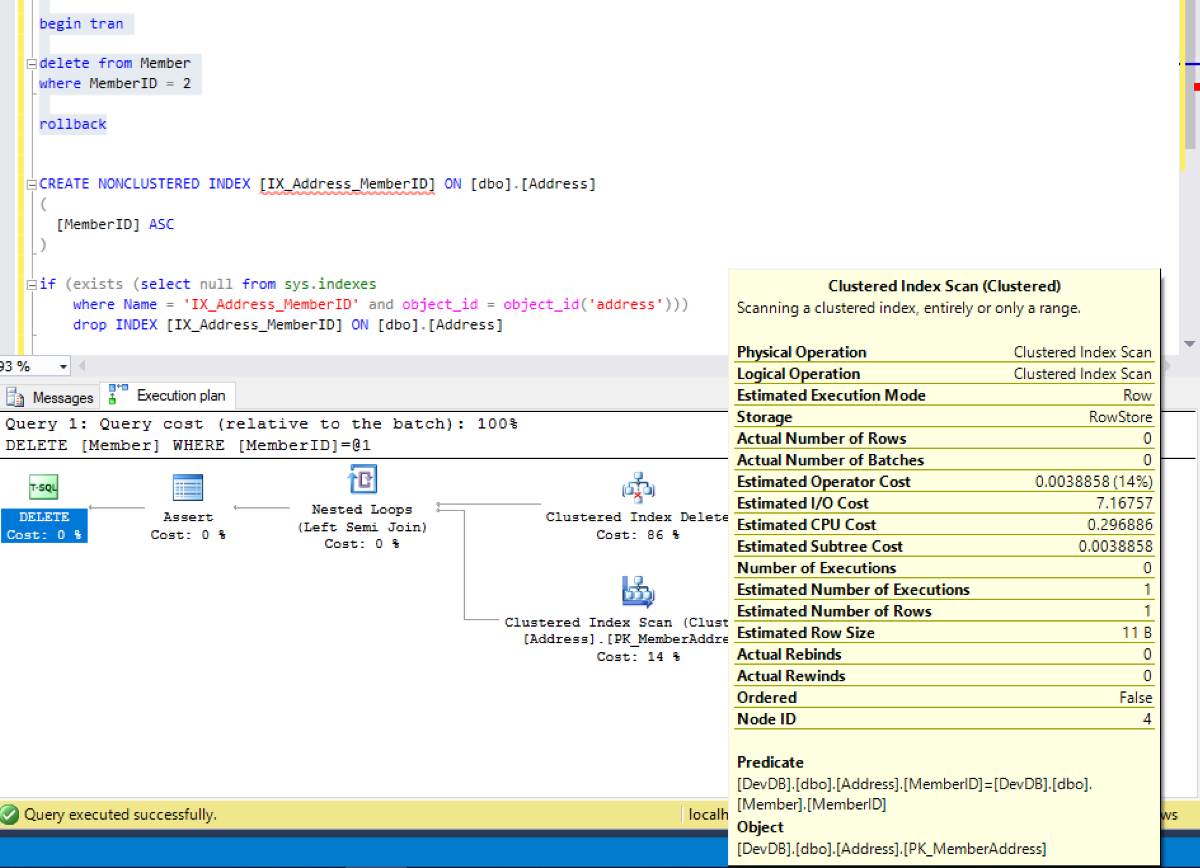
То есть при удалении из записи Member происходит сканирование первичного ключа таблицы Адреса и этого почему-то невидно в статистике IO. Неужели сервер вообще не обращался к страницам данных и ничего не читал? Читал, просто это не отобразилось в статистике IO. Я пытался разобраться в этом вопросе и как я понял, такое бывает из-за параллельного выполнения, что мы и видим тут. Оптимизация, которая сработала в данном случае, но это работает не всегда.
Создаем обратно индекс и пробуем удалить запись снова. Жаль, что статистики снова не видно, но согласно плану выполнения вместо сканирования по первичному ключу будет более быстрый поиск по созданному индексу. То есть индекс повышает скорость удаления в случае с внешними ключами? Да, причем иногда значительно. То же самое и при обновлении данных, которые во внешнем ключе. Да, серверу нужно поддерживать индекс, но это достаточно быстрая операция. У меня был случай, когда не было внешнего ключа на внешнем ключе таблицы с 10 миллиардами записей и обновление, и удаление занимало минуту. После создания индекса эти же операции выполняли практически мгновенно.
Я пока не видел случая, чтобы индекс на внешнем ключе мешал производительности. Возможно, такие случаи и есть, но я пока больше видел доказательств улучшения производительности.
Индексы нужно создавать на колонки, по которым часто ищут, а колонки внешнего ключа явно для того, чтобы по ним искали и не только при операции SELECT, но и при обновлении или удалении.
3. Уникальная колонка – здесь по любому придется поддерживать уникальность. Прежде чем добавлять запись или обновлять вам придется выполнять запрос SELECT, чтобы убедиться в уникальности. Так почему не создать уникальный индекс, который не только ускорит поиск, но и возьмет на себя все проблемы обеспечения уникальности и будет гарантировать уникальность.
4. Колонки, по которым часто ищут данные и тут имеется ввиду условия, которые мы пишем после ON в различных JOIN операциях и в Where. Но таких запросов может быть много и пользователи могут искать по разным колонкам, тогда какие именно колонки выбирать?
Иногда ответ бывает очевидным. Например, в таблице Member скорей всего есть поле Email, по которому мы будем регулярно искать пользователей – при авторизации или каких-то других случаях. Это идеальный кандидат для индекса. Пароль – это поле, которое мы чаще отображаем и оно может быть в операции where, но если и будет там, то скорей всего в сочетании с Email:
Select * from Member where Email = 'nomater@mail.com' and password = 'qwerty'
Конечно при таком запросе достаточно индекса по Email, потому что это уже позволит серверу найти уникальную строку (редко видел базы, где email не уникальный) или малое количество строк, которое потом уже просто проверить на пароль, так что по колонке password создавать индексов не нужно.
Поля, которые не уникальны – явные кандидаты на то, чтобы не создавать индекс – такие как пол. Тут только два значения и индекс скорей всего не принесет пользы. Или следующий запрос:
Select * from Member where LastName = 'Флёнов' and FirstName = 'Михаил'
Можно создать составной индекс из двух колонок LastName и FirstName, но будет ли это эффективно? Индексы по числовым полям более эффективны, чем по строковым, особенно, если строки очень длинные. Просто индексы, как и данные пишутся на диск страницами и индекс не может выходить за его пределы. Чем больше каждая строка в индексе, тем больше он будет занимать места на диске и больше будет требовать операций чтения. Так что размер индекса влияет на его производительность.
Чтобы получить индекс небольшого размера и выиграть в скорости достаточно будет создать его по фамилии. Сервер отфильтрует данные по фамилии и получит достаточно небольшую выборку данных, чтобы потом на них в памяти наложить еще один фильтр по имени.
Я создаю индекс по очевидным колонкам, иду в лайв, а потом уже на сервере слежу за тем, если появляются мои новые запросы среди самых медленных и если появляются, тогда задумываюсь об их оптимизации.
Есть такое мнение, что индексы по строкам работают не эффективно и не дают преимуществ. Заблуждение. Достаточно посмотреть мое первое видео, где на примере строкового поля WSEmail мы создавали индекс и видели, как он эффективно работает и позволяет сделать запрос на много быстрее.
Еще одно заблуждение, что индекс работает со строковыми полями только тогда, когда мы сравниваем знаком равенства и не работает при использовании LIKE. Это и правда и нет. Дело в том, что если знак процента стоит в конце, то SQL Server сможет использовать индекс:
select * from Member where WSEmail LIKE 'noreply@%'
А вот если процент поставить вначале, то индекс уже использоваться не будет:
select * from Member where WSEmail LIKE %@flenov.info'
Или поиск по сайту часто пишут так:
select * from Member where WSEmail LIKE %flenov%'
Так как тут есть символ процента в начале, сервер будет сканировать всю таблицу.
Так что если вы постоянно в своих поисках добавляете знак процента только в конце, то индекс может сделать запросы быстрее.
Напоследок я хотел бы затронуть тему - удаление и обновление записей тормозит индексы. Это правда. Если вы будете вставлять миллион записей из какого-то файла, то индексы могут тормозить импорт, и вы заметите это. Но для таких случаев есть обходные пути, например, временное отключение индексов. Но такие таблицы как Address или Member изменяются не так часто, чтобы боятся индексов.
Замерим скорость работы удаления и вставки записи. У меня удаление получилось 0 ms:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Вставка записей чуть больше – 31 миллисекунда.
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 31 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Я сейчас для примера попробовал создать 8 индексов:
CREATE NONCLUSTERED INDEX [IX_Address_MemberID] ON [dbo].[Address] ([MemberID] ASC) CREATE NONCLUSTERED INDEX [IX_Address_FirstName] ON [dbo].[Address] (FirstName ASC) CREATE NONCLUSTERED INDEX [IX_Address_LastName] ON [dbo].[Address] (LastName ASC) CREATE NONCLUSTERED INDEX [IX_Address_Address1] ON [dbo].[Address] (Address1 ASC) CREATE NONCLUSTERED INDEX [IX_Address_City] ON [dbo].[Address] (City ASC) CREATE NONCLUSTERED INDEX [IX_Address_ZipCode] ON [dbo].[Address] (ZipCode ASC) CREATE NONCLUSTERED INDEX [IX_Address_Phone] ON [dbo].[Address] (Phone ASC) CREATE NONCLUSTERED INDEX [IX_Address_Email] ON [dbo].[Address] (Email ASC)
А теперь попробуем удалить запись:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
9 индексов на таблице с 269,754 не смогли заметно повлиять на удаление записей.
Попробуем добавить запись:
insert into Address (LastName, FirstName, Address1, City, State, ZipCode, Phone)
values ('', '', 'Address', 'New York', 'NJ', '10001', '123123')
Результат:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 15 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
15 миллисекунд! Это даже меньше, чем до создания индекса. Правда это погрешность и если выполнить запрос еще раз он может выполняться чуть дольше. Так что не стоит радоваться и говорить о том, что индекс увеличил скорость вставки, это скорей всего не так, но вот говорить о том, что 8 индексов не смогли заметно повлиять – это да.
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Паника, что-то случилось!!! Ничего не найдено в комментариях. Срочно нужно что-то добавить, чтобы это место не оставалось пустым.

Программист, автор нескольких книг серии глазами хакера и просто блогер. Интересуюсь безопасностью, хотя хакером себя не считаю
Copyright © 2025 Михаил Флёнов. Тираж 1 штука. Отпечатано на ноутбуке. А за права отвечаю, или постараюсь.
А здесь еще и копирайт поставлю: Professional Web Development.
На сайте используются Cookie. Если вы из ЕС или Калифорнии США, то вы должны согласиться с их использованием - Согласен. Если вы из нормальной страны, то вам пох.


Добавить Комментарий