Продолжим знакомится с производительностью базы данных MS SQL Server и как ее улучшить и сегодня я решил рассказать про две примерно смежные темы - фрагментация индексов и статистика. Обе темы объединяют как раз индексы и они влияют на их производительность, поэтому я решил рассмотреть их одновременно.
Фрагментация индексов и некорректная статистика может повлиять на производительность базы данных и как SQL Server выполняет запросы. Сервер по умолчанию собирает статистику сам и нам не нужно заботиться о ней. При создании индексов можно указать – обновлять статистику автоматически или нет и по умолчанию как раз все обновляется.
Начнем со статистики, которая показывает, как много данных определенного типа и это может сильно повлиять на выполнение запроса. Например, есть запрос:
Select * From Member m Join Address a on m.MemberID = a.MemberID Where m.LastName = 'Иванов'
Статистика скорей всего покажет, что после фильтрации по фамилии в результате получиться всего несколько записей и проще будет для каждой из них найти адрес в таблице адресов – то есть выполнить loop join.
Select * From Address a Join City c on a.CityID = c.CityID Where a.CountryName = 'Лапландия'
Здесь уже поиск по первой таблице может вернуть множество строк и для каждой из них искать город во второй будет невыгодно. В зависимости от ситуации, сервер может выбрать hash или merge join.
Сколько строк может вернуться говорит нам статистика и чем лучше статистика, тем точнее результат.
Если честно, я никогда не отключал обновление статистики и не знаю, в каких случаях это может пригодиться, поэтому из личного опыта нечего рассказать. Но что я могу сказать, так это мне приходилось встречаться с случаями, когда статистика была неверна и это значительно влияло на производительность, в негативную сторону. Средние по размеру запросы с большим количеством логики и Join начинали сильно тормозить.
Чаще всего с потерей корректности статистики мне приходилось сталкиваться сразу после восстановления большой базы данных. Сразу после этого очень даже рекомендую обновить статистику на базу данных и это легко делается выполнением команды:
sp_updatestats
В зависимости от размера базы данных эта команда может выполняться достаточно долго, но это очень важно. Если необходимо работать над оптимизацией запроса и вы делаете это при не оптимальных индексах – это трата времени, потому что в реальности вы будете оптимизировать запросы под не оптимальную систему, а после обновления статистики может произойти как улучшение производительности, так и падение.
Чтобы обновить статистику только для определенной таблицы, можно выполнить следующий запрос:
UPDATE STATISTICS ИмяТаблицы
Этот запрос уже более безопасный и достаточно быстрый и я его без проблем выполнял на огромных таблицах на рабочем сервере, правда под минимальной нагрузке. При сильной нагрузке я бы не выполнял этот запрос, потому что он приводит к перекомпиляции запросов и это реально имеет смысл – ведь если статистика изменилась, то и план выполнения может измениться на более оптимальный. А если вы выполните обновление, но реально ничего не изменилось, перекомпиляция будет бессмысленной.
В принципе, выполнять обновление статистики можно, но не слишком часто. Работая над Sony сайтами, я никогда не выполнял полное обновление sp_updatestats, но регулярно выполнял UPDATE STATISTICS на отдельных таблицах.
У меня на канале есть видео, в котором я рассказываю, как я находил медленные запросы. На моем сайте есть и текстовая версия этого видео (Поиск медленных запросов). Если появлялись медленный запрос, который раньше выполнялся быстро, то первым делом я обновлял статистику всех таблиц, которые вовлечены в запрос и если не помогало, тогда уже переходил к исследованию, что произошло и как улучшить производительность.
Второй вопрос, который я хотел бы сегодня обсудить – это дефрагментация и перестроение индексов.
Когда вы только создали индекс, то его данные последовательны и все счастливы. Со временем и после большого количества вставки записей может случиться так, что данные будут разбросаны по базе данных и их нужно будет реорганизовать.
Чтобы определить фрагментацию индекса кликаем правой кнопкой по индексу и выбираем пункт Свойства. В появившемся окне выбираем слева Fragmentation и здесь можно увидеть наверху заполненность страниц и фрагментацию:
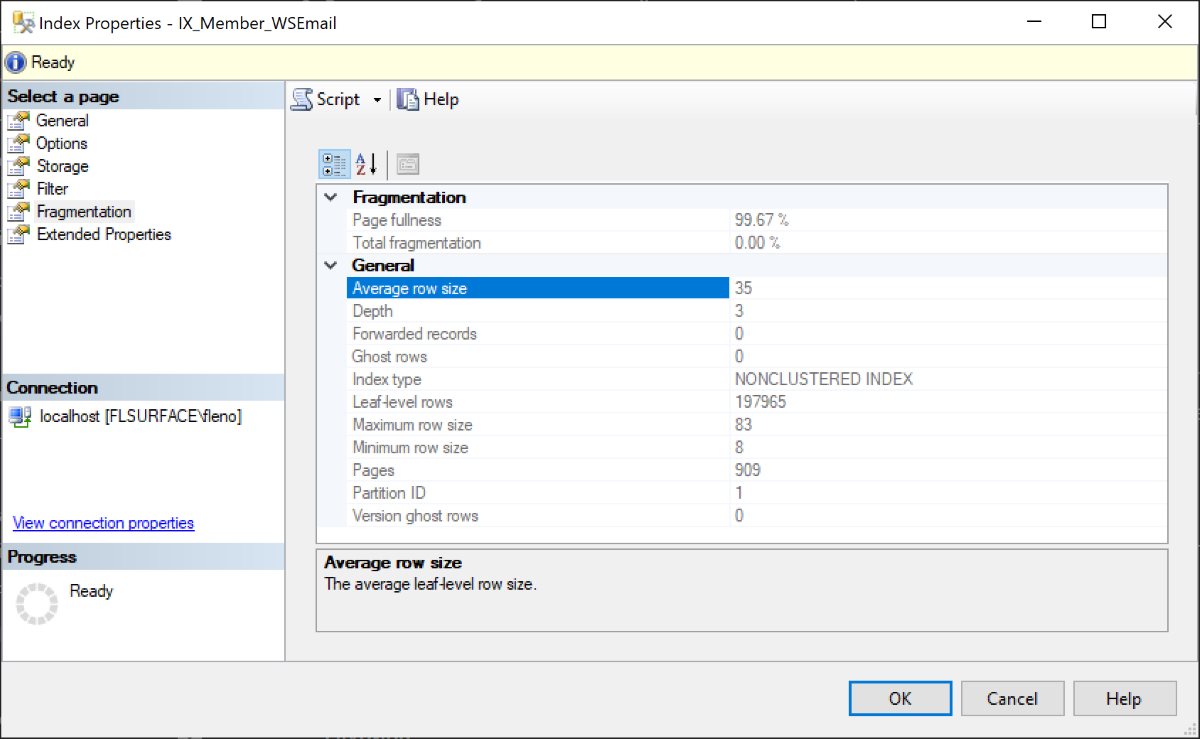
В моем случае заполненность почти 100 процентов, но фрагментации нет, потому что это такая база, куда не вставляется большого количества записей, это локальный тест.
Такая высокая заполненность получилась за счет того, что у меня Fill Factor установлен в 0. Фактор заполненности можно увидеть в разделе Options. Попробую его установить в 50 и если нажать OK, то индекс будет пересоздан и заполненность сократиться до 50.
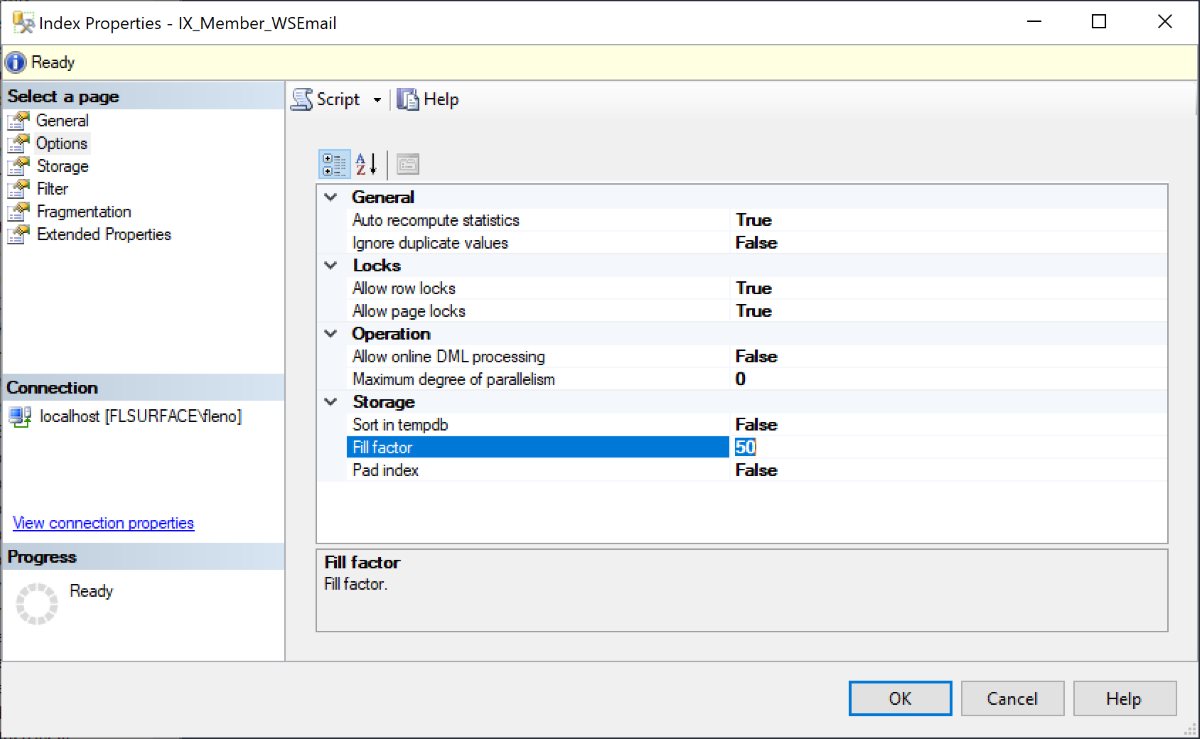
Теперь в каждой странице индекса данные заполнены только на 50% и там достаточно пространства для вставки новых данных, и эта операция будет происходить очень быстро. В чем прикол? Почему не сделать 50% по умолчанию? Дело в том, это нужно далеко не всегда. Если это первичный ключ с авто увеличивающейся колонкой, в который данные всегда добавляются в конец, нет смысла выделять пустое пространство в каждой странице. Если это данные, где новая строка может вставляться в любое место, можно оставить 80 или даже 60 процентов пустого пространства. Все зависит от того, как часто вставляются данные и как часто читаются.
Если страницы индекса заполнять только на 50%, понадобиться больше страниц и серверу во время поиска придется читать больше данных с диска, что сократит немного производительность. Заполненность индекса может сократить скорость вставки, но замедлить чтение.
Чтобы определить текущую фрагментацию на базе данных с именем DevDB можно выполнить следующий запрос:
SELECT a.index_id, name, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID(N'DevDB'),
NULL, NULL, NULL, NULL) AS a
JOIN sys.indexes AS b
ON a.object_id = b.object_id AND a.index_id = b.index_id;
Теперь зная убитые индексы можно в SQL Server Management кликнуть на каждом из них и выбрать Reorganize или выполнить следующий запрос:
ALTER INDEX Имя_Индекса ON Имя_Таблицы REORGANIZE;
Можно реорганизовать индекс и сразу же поменять заполненность:
ALTER INDEX Имя_Индекса ON Имя_Таблицы
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON,
STATISTICS_NORECOMPUTE = ON);
Вместо имени индекса можно указать ALL, если вы хотите реорганизовать все индексы на таблице.
Для дефрагментации последнее время я использую скрипт https://github.com/MichelleUfford/sql-scripts/blob/master/indexes/dba_indexDefrag_sp.sql. Я создаю эту хранимую процедуру у себя в базе данных и потом ставлю следующий скрипт на выполнение каждый месяц в определенный день. Когда я отвечал за базу данных, то этот скрипт у меня бегал каждый понедельник в 3 часа ночи, когда самая минимальная нагрузка на базу данных:
EXECUTE dbo.dba_indexDefrag_sp
@executeSQL = 1
, @printCommands = 1
, @debugMode = 1
, @printFragmentation = 1
, @forceRescan = 1
, @maxDopRestriction = 1
, @minPageCount = 8
, @maxPageCount = NULL
, @minFragmentation = 5
, @rebuildThreshold = 30
, @defragDelay = '00:00:05'
, @defragOrderColumn = 'page_count'
, @defragSortOrder = 'DESC'
, @excludeMaxPartition = 1
, @timeLimit = NULL
, @database = 'mamberdatabase,pointsystem';
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Паника, что-то случилось!!! Ничего не найдено в комментариях. Срочно нужно что-то добавить, чтобы это место не оставалось пустым.

Программист, автор нескольких книг серии глазами хакера и просто блогер. Интересуюсь безопасностью, хотя хакером себя не считаю
Copyright © 2025 Михаил Флёнов. Тираж 1 штука. Отпечатано на ноутбуке. А за права отвечаю, или постараюсь.
А здесь еще и копирайт поставлю: Professional Web Development.
На сайте используются Cookie. Если вы из ЕС или Калифорнии США, то вы должны согласиться с их использованием - Согласен. Если вы из нормальной страны, то вам пох.


Добавить Комментарий