Самый простой способ сохранять данные в большой массив – добавлять их в самый конец данных. Рассмотрим телефонный справочник. Мне как-то говорили в комментариях, что на телефонном справочнике проще воспринимается информация, потому что эта проблема понятна всем.
Итак, у нас есть таблица:
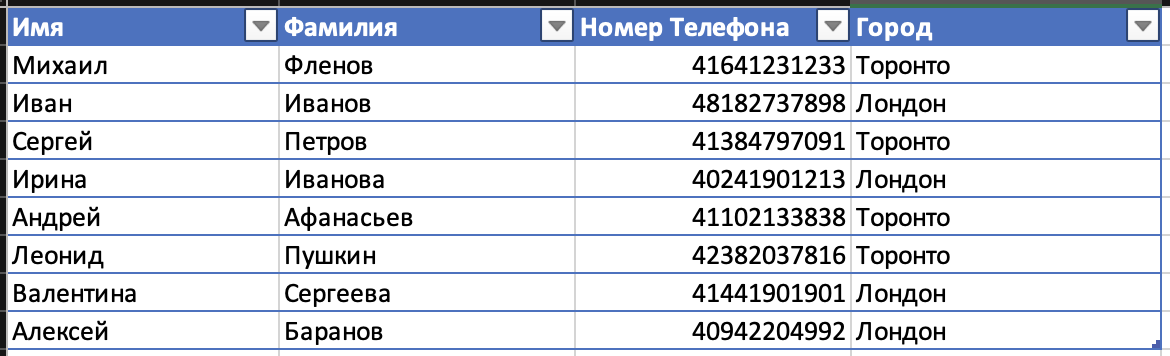
Как нам найти телефонный номер для Михаила Фленова? Берем первую запись здесь и тут же натыкаемся на мою фамилию и о чудо, с первого раза мы нашли нужную информацию. Но это идеальный случай, а если нам нужно найти телефон Баранова Алексея? Вот тут мы уже вынуждены будем идти по каждой строчке, сравнивать каждую из них и в результате будет 8 проверок. Это уже не весело.
Как можно ускорить поиск? Вариант есть, но для этого данные должны быть отсортированы и тогда мы сможем использовать классическое решение задачи поиска – бинарный поиск. Можем ли мы хранить в базе данных данные в отсортированном виде? Без проблем, давайте так и сделаем:
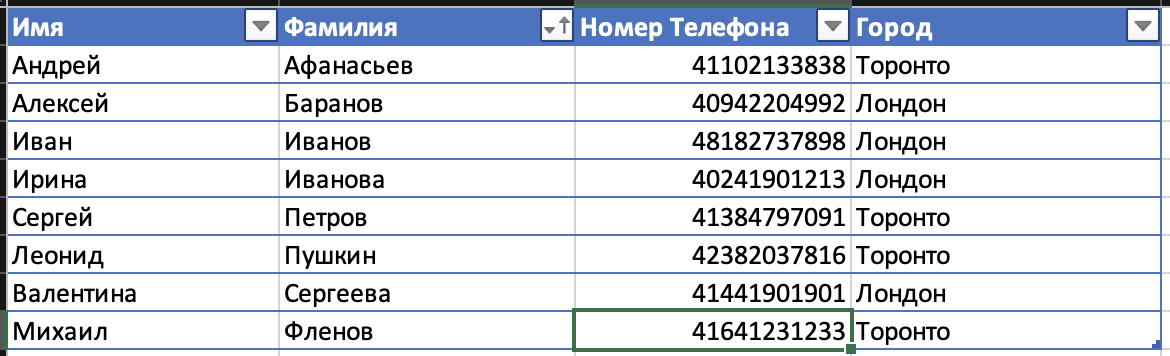
Смысл бинарного поиска – делить данные пополам и смотреть – текущее значение больше или меньше нужного. Допустим, что мы снова ищем мой телефон. Середина списка – это Иванова Ирина или Сергей Петров, потому что центр проходит прямо посередине. В таком случае округляем и берем любую из них, допустим, мы выбрали на удачу Петрова Сергея. Фамилия Фленов идет до или после Петров? После! Значит все, что до Ивановой точно отпадает, ведь список отсортированный и до не может быть фамилии на букву Ф.
Значит нужная нам фамилия во второй половине списка:

Берем опять элемент в центре, это Валентина Сергеева и проверяем – нужная нам фамилия больше, или меньше? Она больше, значит снова берем вторую половину, где как раз и осталась нужная нам фамилия.
Всего три сравнения и мы попали на нужную нам запись.
Значит, чтобы мы могли быстро находить записи по фамилии мы должны хранить в базе данных информацию в отсортированном виде по фамилии.
Проблема решена? В принципе да, но. . . Телефоны ищут не только по фамилии, достаточно часто искать приходится и владельца по номеру телефона. Но так как у нас данные отсортированы по фамилии, в случае поиска по номеру мы вынуждены будем сканировать все записи. Разве что вы знаете способ, как хранить данные одновременно отсортированными по телефону и по фамилии. Я такого способа не знаю.
Вернемся обратно к не отсортированным данным и вместо сортировки добавим новую колонку и назовем ее Key. Можете воспринимать это как первичный ключ, но для нас это будет как бы адрес, где находиться запись. То есть по адресу 1 находиться мой телефон, по адресу 2 это телефон Ивана Иванова и так далее.
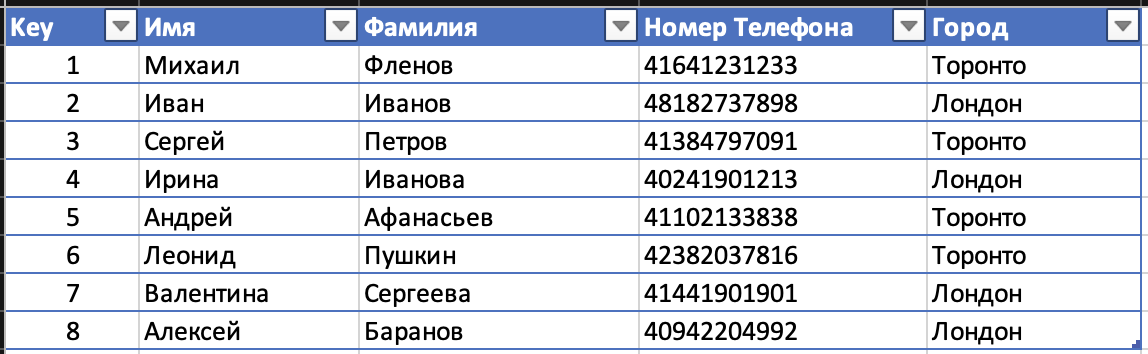
dbtable4.png
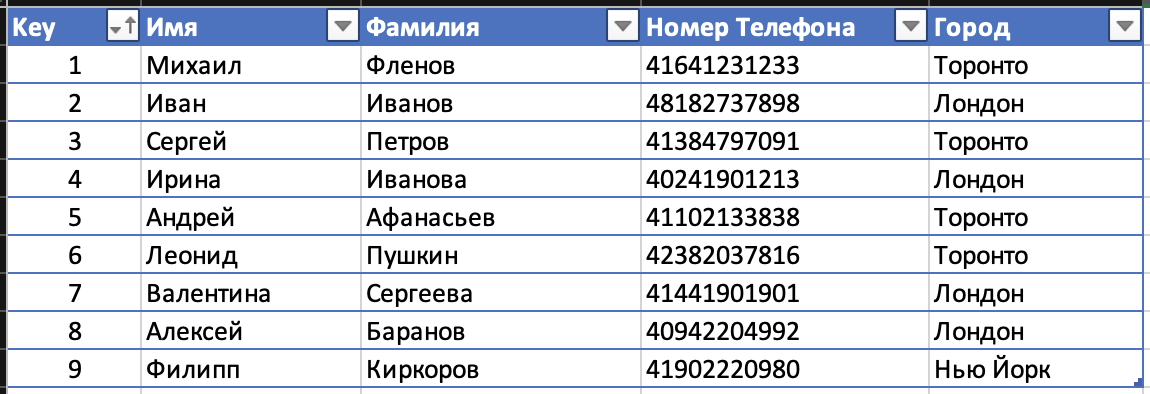
Теперь вместо сортировки самих данных можно создать два индекса:
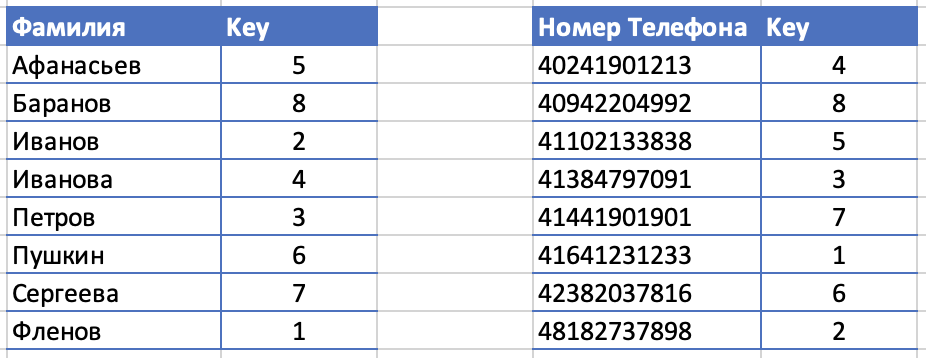
Слева индекс по фамилии, справа индекс по телефону. Оба отсортированы, а значит мы можем использовать бинарный поиск для того, чтобы найти нужные нам записи. Нужно искать по фамилии, мы берем левую таблицу, находим нужную фамилию и тут же видим Key – адрес, где находятся сами данные телефонной записи.
Проблема такого плоского индекса в том, что он плоский и нам постоянно нужно искать середину. Поддержка даже плоского индекса потребует затрат, ведь каждый раз, когда мы добавляем запись в базу данных нам нужно пересчитать два индекса и вставить новую запись в нужную позицию.
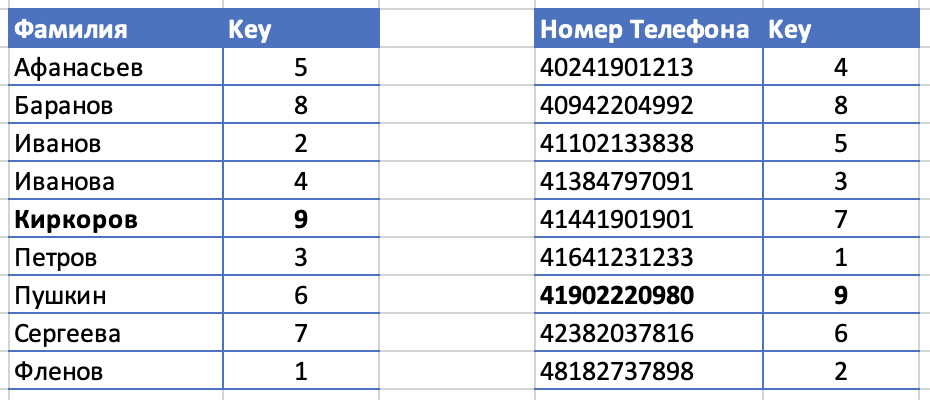
Допустим, что мы добавляем новый телефон для Киркорова. В случае с основной таблицей мы просто добавляем его в конец и даем новый номер 9:
Добавлять данные в конец очень просто и легко, много затрат не нужно. А вот в случае с индексом, нам нужно вставить данные в середину и подвинуть остальные данные в конец.
У вас есть десять кубиков, которые стоят в ряд. Чтобы поместить один в середину, нужно сначала подвинуть кубики, которые мешают в сторону, раздвинуть себе немного места и туда мы уже сможем вставить кубик.
Точно так же и с данными. И поддержка такого индекса может оправдать себя в огромном количестве случаев. Как часто мы добавляем телефоны? Уверен, что на много реже, чем мы ищем. Лучше затормозить одну операцию вставки новых данных и ускорить поиск, который может происходить сотни раз в секунду.
Раз уж мы так заморачиваемся и создаем плоский индекс, так может сделать что-то, чтобы нам не приходилось каждый раз искать середину? Может просто взять и расположить данные как-то в таком порядке, чтобы не приходилось постоянно искать эту середину?
Без проблем. Берем середину и ставим ее во главу нашей структуры данных. Теперь это Киркоров, он как раз удобно расположился в центре. Слева располагаются все имена, которые идут по алфавиту раньше Киркорова, а справа будут те, чьи фамилии после Киркорова.
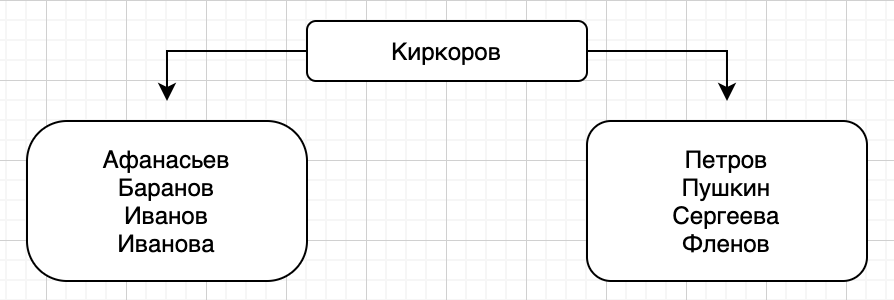
Искать теперь будем начинать с центрального главного блока, то есть с Киркорова. Если мы снова ищем мой телефон, то теперь вместо поиска середины, мы начинаем с середины и сравниваем, - Фленов больше Киркорова? По росту точно нет, а вот фамилия по алфавиту расположена позже, значит мы должны двигаться на правый блок, где отсортированы данные, но нам нужно искать середину. Вместо поиска это середины, может разделить и этот блок? Это можно:
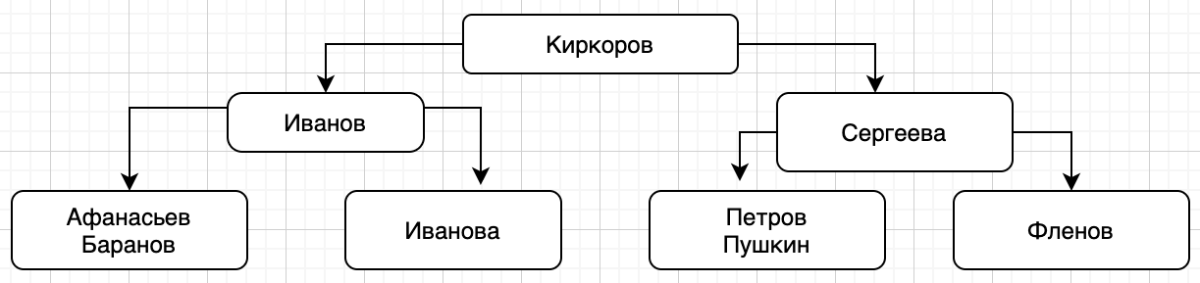
Опа, у нас получилось дерево! На третьем уровне в двух блоках по две фамилии и их можно разбить на два отдельных блока:
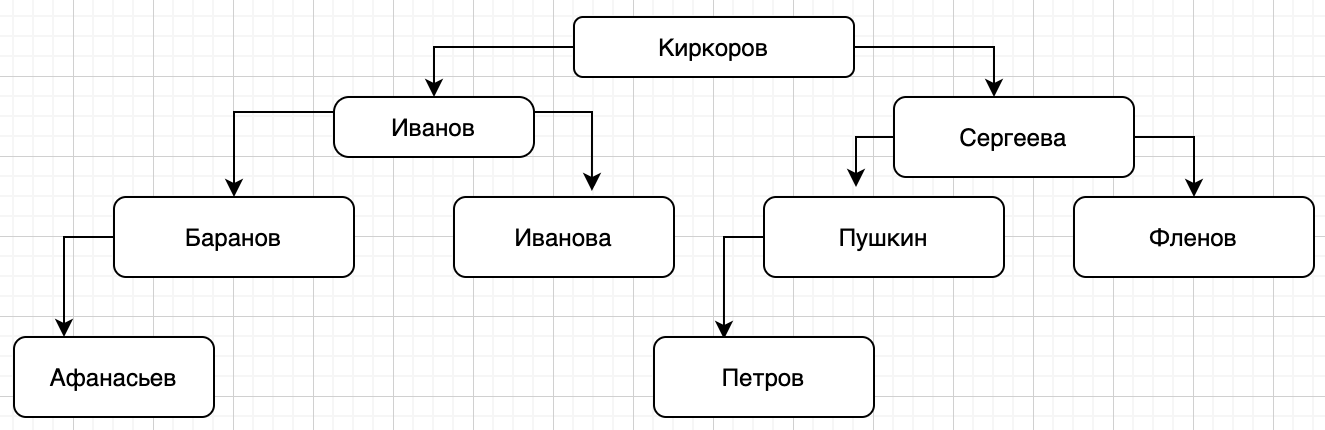
Вот теперь точно дерево и у каждого элемента только два подчиненных, причем слева всегда элемент меньше или в данном случае по алфавиту стоит выше, а справа больше, или по алфавиту стоит позже.
В программировании обычно балансируют такие деревья по-другому, но для нашего случая это не важно, мы сейчас не деревья проходим, а смотрим на принцип в целом.
Раз уж заморачиваться с индексом, так уж лучше построить такую систему, потому что теперь нам не нужно искать середину. Мы начинаем с середины. Если мы ищем Фленова, то мы двигаемся вправо и оказываемся в середине второй половины списка. В принципе, мы все еще ищем практически бинарным поиском, идея все еще та же, просто мы не рассчитываем больше середину, она уже рассчитана. Мы построили дерево из всех возможных вариантов.
Глядя на дерево мы можем сказать, что максимальная сложность поиска по всем элементам – 4 проверки. 9 элементов в списке простым перебором потребует 9 проверок, а в случае дерева/бинарного поиска только четыре. Скажу больше, если элементов будет 15, то сканирование всех займет 16 проверок, а по дереву только 4, потому что у нас еще место в дереве для еще 6 элементов.
Список из 31 элемента можно будет просмотреть максимум из 5 проверок, список из 63 элементов максимум за 6 проверок и так далее. Крутизна!
Но с точки зрения компьютера такое дерево не совсем эффективно. Дело в том, что компьютер не так эффективно читает по небольшому блоку информации. Да и постоянно перестраивать это дерево тоже будет не очень выгодно после каждой вставки данных.
Я сейчас гугланул и мне умный интернет сказал, что в случае с SSD дисками минимальная единица чтения или записи составляет 4 килобайта. Даже если нам нужен 1 байт с диска, он все равно прочитает физически 4 килобайта, и мы из них возьмем только 1 байт.
Если мы храним данные в Unicode, каждый символ может занимать от 1 до 4 байт. Допустим, что все символы 4 байта, а значит в одном блоке может поместиться 1024 символа. Если фамилия в базе данных занимает 20 символов, то мы только что прочитали с диска 4kb только для того, чтобы реально использовать 20 * 4 или 80 байт. Ужас. Может все же хранить данные плотнее в нашем дереве и пусть каждый блок дерева будет занимать 4 килобайта? В этом случае мы за раз прочитаем больше данных и потом в памяти просто пробежимся сразу же по всему содержимому блока.
MS Sql Server использует в качестве размера блока 8 килобайт, по крайней мере в документации все еще такая цифра.
Помимо уплотнения данных нам нужно подумать еще и про эффективность добавления и обновления данных. Давайте каждый блок данных заполнять не полностью и оставлять место для новых данных. Отлично, базы данных позволяют это делать и размер пустого пространства в блоке настраивается.
Итак, мы сохраняем ту же самую идею, но только в каждый блок дерева должны записать чуть больше данных и еще и оставить пустое пространства:

В корень дерева я взял каждый четвертый элемент, то есть 4-ю и 8-ю запись нашей таблицы. Теперь когда мы ищем Баранова, мы читаем корневой блок и проверяем первый элемент в блоке – он Иванова больше Баранова – Да, значит мы должны взять блок, ссылка на который расположена слева и мы попадем в левый нижний блок.
Если мы ищем Киркорова. Опять читаем корневой блок и проверяем Иванова больше Киркорова? Нет, проверяем Сергеева больше Киркорова? Да, значит читаем блок, ссылка на который находиться слева от Сергеевой.
Отлично, за два чтения с диска мы смогли найти нужную фамилию.
Так как в блоках есть пустое пространство, то мы можем без проблем добавлять данные. Допустим, что мы хотим добавить фамилию Бережной. Уже визуально мы видим, что эта фамилия принадлежит левому нижнему блоку. Мы читаем этот блок, вставляем в памяти новую фамилию и записываем обратно 4 килобайта. Одно чтение, одна запись и мы обновили индекс.
Базы данных немного варьируются в том, как они хранят индексы, но в целом идея такая. Просто бывают разные типы деревьев B-Tree и B+Tree.
Если говорить о таблице пользователей на сайте, то сколько записей мы можем вставить в день? Сколько пользователей регистрируется в день? Даже если будет 24 тысячи в сутки (это достаточно много) это будет 1 тысяча в час или чуть менее 17 в минуту или целых 3.5 секунды на одну вставку. Базе данных понадобиться миллисекунды на то, чтобы прочитать и обновить блок индекса, так что не бойтесь индексов, главное правильно их настраивать.
А что если мы заполним блок до предела, а предел у нас будет 6 фамилий:
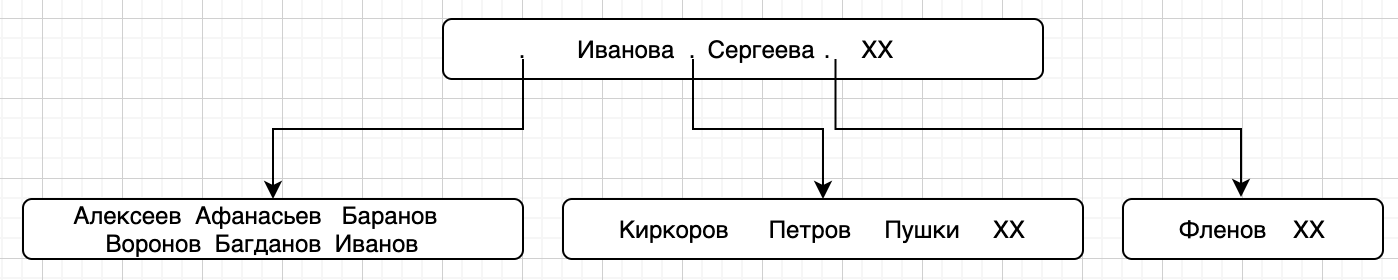
Теперь мы хотим вставить новую фамилию – Андреев. Без проблем, нужно просто разбить один блок на несколько, точно также, как у нас разбит корневой:
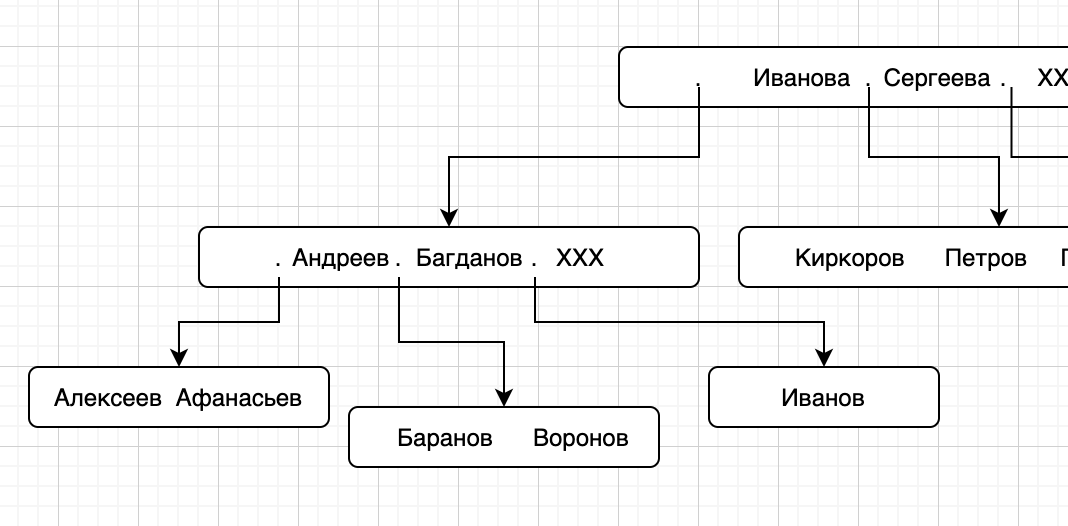
Если мы продолжим вставлять записи на буквы А и Б, то наше дерево будет дробиться и смещаться влево. Количество уровней слева может оказаться на много больше количества уровней справа и тогда поиск данных слева будет медленнее. Для того, чтобы решить эту проблему нужно хотя бы иногда делать реорганизацию индекса, чтобы база сбалансировала дерево.
Базы могут запрещать создавать индексы на колонки, размер которых не помещается в страницу, для SQL Server это 8 килобайт. В этом также есть свой смысл, потому что если одна колонка индекса не помещается в минимальную единицу чтения, то какой смысл от такого индекса? Он будет очень медленным.
Вообще эффективность индекса зависит еще и от размера данных в нем. Если индекс построен на числовую колонку для 4 байтовых чисел, то прочитав одну страницу мы получаем 8096 байт данных или 2024 числа. Это конечно не совсем правда, потому что там еще будет служебная информация, но все равно, даже если мы получим за раз 1 тысячу чисел, это уже круто. Поэтому индексация по числовым колонкам дает максимальную эффективность.
Индексы могут создаваться по нескольким колонкам, можно создать индекс по Фамилии и Имени, но добавлять имя в индекс может быть не эффективным, потому что это раздует дерево индекса и затормозит его. Очень часто проще найти всех Фленовых по индексу и потом уже отфильтровать результат по имени без индекса.
Индексы бывают кластерными и не кластерные. Кластерные – это когда сама строка с данными будет находиться в индексе, обычно для этого выделяют самые последние блоки (самые нижние), их называют листьями дерева. Может быть только один кластерный индекс, потому что в нем хранятся уже сами данные – вся строка телефонной записи – имя, фамилия, номер телефона. Хранить все эти данные в двух разных индексах – теоретически возможно, но это бред, потому что это только раздует базу.
Проще создать остальные индексы не кластерными, где на листьях дерева находится только информация о том, где найти данные, обычно в листьях дерева хранится просто первичный ключ. То есть по не кластерному индексу, который создан для колонки Фамилия мы находим первичный ключ, а потом по первичному ключу ищем по кластерному индексу сами данные.
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Паника, что-то случилось!!! Ничего не найдено в комментариях. Срочно нужно что-то добавить, чтобы это место не оставалось пустым.

Программист, автор нескольких книг серии глазами хакера и просто блогер. Интересуюсь безопасностью, хотя хакером себя не считаю
Copyright © 2024 Михаил Флёнов. Тираж 1 штука. Отпечатано на ноутбуке. А за права отвечаю, или постараюсь.
А здесь еще и копирайт поставлю: Professional Web Development.


Добавить Комментарий